

Dataizm, Big Data
01.07.2018 | İlker Dikmen
gembaakademi.com
Dataizm, Big Data
Öyle görülüyor ki içinde bulunduğumuz yüzyılda bilim kurgu filmlerinde izlediğimiz birçok şey beklediğimizden daha hızlı bir şekilde gerçek olacak. Sosyal, endüstriyel, biyoteknoloji gibi birçok alanda şirketler ciddi bir yarıştalar. Bu yarışın önemli bir kısmı ise veri alanında gerçekleşiyor. Kişişel veri toplama ve analizi (zenginleştirilmiş veri) anlamında Google ve Facebook gibi şirketler dikkat çekici çalışmalar gerçekleştiriyor. Facebook yaptığımız paylaşımlardan; kişisel özelliklerimiz, siyasi görüşümüz, ilgi alanlarımız ile ilgili analizler yapabiliyor. Peki benim kişisel fikirlerim, ilgi alanlarım yada siyasi görüşüm Facebook’un ne işine yarar? Bireysel olarak bir işe yaramasa da populasyonun büyük bir bölümünü değerlendirdiğimizde hangi bölgede hangi ürünlerin daha fazla satılacağı konusunda pazarlamacılara hiçbir zaman elde edemeyecekleri kadar tutarlı bilgiler satabilir. Yine en küçük yerleşim yeri dahil olmak üzere hangi siyasi partinin ne kadar sempatizanı olduğu bilgisi küçük sapmalarla tahmin edilebilir. İşin enteresan tarafı Facebook bu verileri toplamak için fazla da zahmete katlanmıyor. Milyonlarca (2018 yılında 2 milyar 167 milyon olarak tespit edilmiş ) kullanıcı bu verileri gönüllülükle paylaşarak şirketi inanılmaz bir işgücünden kurtarmış oluyor. Aksi taktirde dünyanın her yerinde binlerce araştırmacı kapı kapı dolaşsa bile bu verileri elde etmesi pek mümkün olmazdı.
Endüstri 4.0
Big Data (Büyük Veri ya da Zengin Veri) kavramı şüphesiz her sektör için bu yüzyılın vazgeçilmezi olacak. Ancak teknoloji konusunda bilinçli tüketici olduğumuz söylenemez. Endüstri 4.0 yada Big Data isimlerini duyunca bir anda çağ atlayacağımızı düşünüp kesenin ağzını açıyoruz. Endüstri 4.0 deyince aklımıza hemen insansız fabrikalar geliyor ve bir anda solucan deliğinden geçip işletmemizi orada görecekmişiz hissine kapılıyoruz. Aynı şekilde Big Data ismini duyduğumuzda da milyonlarda verinin karmaşık analizleriyle işletmemizi zirveye taşıyacağımızı hayal edip kesenin ağzını açıyoruz. Şüphesiz endüstri zamanla bu durumlara evrilecek. Özelllikle işgücünün pahalı olduğu Avrupa, Amerika gibi ülkeler bu işi hayata geçirmeye mecbur ve de çoktan başladılar. Ancak bu işi bilinçli bir şekilde yönetemediğimizde büyük umutlarla yaptığımız yatırımlar altında eziliriz. Tabii o kadar parayı harcadıktan sonra aman yeterki yaşasınlar diye kendimizi bu sistemlere hizmet ederken buluruz.
Sık karşılaştığımız yanlışlardan biri de veri toplama yapısını oluşturmadan önce hangi verilere ihtiyacımız olduğunu tespit edememekten kaynaklanır. Bu durumda büyük maliyetlerle topladığımız veriler süreç çıktılarıyla ilişkilendirilemez ve elimizde katma değersiz veri yığınları oluşur.
Diğer yanlış ise elimizde bulunan verileri doğru analiz edememekten kaynaklanır. Yani girdilerin çıktıyla ilişkisi, girdilerin etkileşimleri ve bu etkileşimlerin çıktıyla ilişkisi gibi analizlere yapamadığımız taktirde yine bir veri çöplüğüne sahip olmanın ötesine geçemeyiz. Dolayısıyla ham veri ancak zengin veri haline getirildiğinde katma değer sağlar.

Bilgisayar destekli makinaların, robotların imalata girmesiyle birlikte online veri alma işlemi kolaylaştı. Binlerce veri sistemimizde kayıt altına alınabiliyor ve istediğimizde bu verileri kullanabiliyoruz. Peki bu verileri ne kadar etkin kullanabiliyoruz?
Zengin Veri
Aşağıdaki tabloda plastik enjeksiyon ile imalat yapan bir işletmede çevrim zamanı değerlerini görüyoruz. Ardışık 415 adet parçanın (yaklaşık 4.5 saat) çevrim zamanı ölçülerek ortalama çevrim zamanı 39.47 sn olarak tespit edilmiş. Peki bu veri bize ne kadar katkı sağlar?
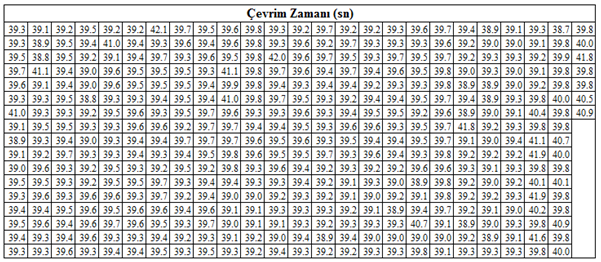
Elimizdeki 415 adet veriyi uygun araçlarla analiz edersek bize katma değer sağlayacak aksiyonun tespiti için yol gösterebilir. Gorsel 2’de verilerin dağılımını yorumlayan bir analist şu soruları sorar:
- 0.4729 standart sapma ile doğru planlama yapabilir miyim?
- Standart sapmayı düşürmek yani çevrim süresini daha kararlı hale getirmek için nasıl bir yol izlemeliyim?
- Yapacağım iyileştirme metot değişikliği mi olmalı? Yoksa gecikmeler için hızlı kaizenler mi yapmalıyım?
- Maksimum faydayı sağlamak için grafiğin hangi bölümüne odaklanmalıyım?
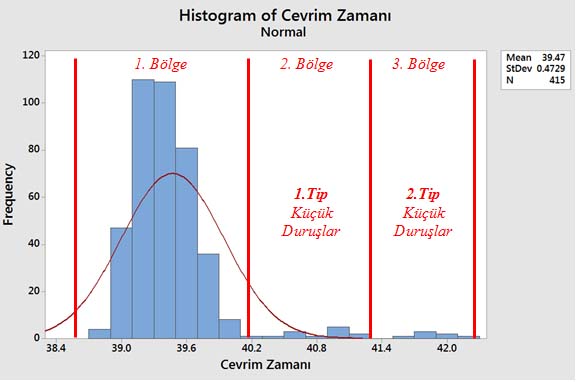 Grafikte açıkça standart çevrim zamanını bozan küçük gecikmeler (Chokote) olduğunu görüyoruz. Genellikle bu tür küçük duruşlar kayıt altına alınmadığı için performans kayıpları olarak gözükür. Bu tür kayıplar incelendiğinde bant sıkışmaları, vakum problemi, parça düşmesi, basınç hatası gibi çözümü çokta zor olmayan birçok iyileştirme fırsatı ortaya çıkar.
Grafikte açıkça standart çevrim zamanını bozan küçük gecikmeler (Chokote) olduğunu görüyoruz. Genellikle bu tür küçük duruşlar kayıt altına alınmadığı için performans kayıpları olarak gözükür. Bu tür kayıplar incelendiğinde bant sıkışmaları, vakum problemi, parça düşmesi, basınç hatası gibi çözümü çokta zor olmayan birçok iyileştirme fırsatı ortaya çıkar.
Histogram ile çevrim zamanına benzer şekilde, enerji tüketimi, makine yada operatör başına üretim adedi, yedek parça ömrü gibi birçok analiz yapılabilir.
Bir başka analiz aracı olan Bubble Plot örneğini Görsel-3’de görüyoruz. SAS Institute Inc. tarafından hazırlanmış olan rapor bize bir bölge için, kategori bazında araç tercihlerini sunuyor.
Türkiye İstatistik Kurumu tarafından toplanmış olan veriler ile oluşturulmuş Görsel-4’te Türkiye genelinde sinema izleyicilerinin yıllara göre yerli ve yabancı sinema tercihlerini görüyoruz.
Bu basit grafiğe bakarak yerli sinemaya olan ilginin -2016 yılı hariç- istikrarlı bir şekilde arttığını görebiliyoruz. Aynı şekilde 2000-2005 arasında yabancı sinema izleyicisi azalmış sonrasında ise yine istikrarlı bir şekilde artış göstermiştir. Eğer sinemaya olan ilgiyle çeşitli faktörler arasında bir ilişki kurabilirsek, zaman yolculuğu yaparak önümüzdeki 2025 yılında durumun nereye gideceğini tahmin edebiliriz. Bir sinema yapımcısı için bu analizin ne kadar değerli olduğunu düşünebiliyor musunuz?
Verilerle Yönetmek
Sosyal medya, siyaset ve hizmet sektöründe istatistiksel metodların kullanımı ile ilgili örnekler çoğaltılabilir. Hayatımızın her alanında kontrollü ya da kontrolsüz şekilde giren veri analizi, üretim sektöründe de kullanılmak durumundadır. Birçok istatistiksel yazılım bize hem sahadan gelen canlı veriyi hem de önemli proses parametrelerinin farklı düzeylerdeki değerleriyle deneyler tasarlayıp ideal iş modellemeleri oluşturma imkanı sağlıyor. Tabi ki bunun için öncelikle veri analizi konusunda yeterli personel ihtiyacı ortaya çıkıyor. Teknolojinin gelişmesine paralel olarak onu etkin kullanacak uzman personellerin yetişmesi sayesinde güvenilir iş modellemeleriyle kararlı prosesler yaratmak eskisi kadar zor olmayacak.
Tabi veri analizi metodları geliştikçe karşımıza daha karmaşık grafikler de çıkıyor. Çubuk, pasta, çizgi grafiği gibi herkesin kolaylıkla anlayabileceği araçların kullanımı devam edeceği gibi bunların yetersiz kaldığı durumlarda alternatif grafikler hayatımıza girmeye başladı.
Görsel 5’te bir Damla Çikolatalı Kurabiye üretiminde için önemli olduğuna karar verilmiş 4 farklı faktörün 2 ya da 3 farklı düzeyi için yapılmış olan Lezzet Testi deneyinin analiz sonuçlarından birini görüyoruz.
Bu deneyde çikolata türü (Bitter-sütlü), Çikolata miktarı (30-40-50 gr), Tereyağ miktarı (110-120-130gr) ve Buzdolabında Dinlenme Süresi (25-35-45) değişkenleri alınmış. Bu değişkenlerin oluşturduğu kombinasyonlarla hazırlanan kurabiyeler müşterilere tattırılarak 100 üzerinden puan vermeleri istenmiş(Graifiği oluşturan verilerin bir kısmı konuyu açıklayabilmek için manipüle edilmiştir).

Elde edilen değerler Multi-Vari grafiği ile değerlendirildiğinde;
- Bitter çikolata kesinlikle daha başarılı
- Buzdolabında dinlenme süresinin lezzet skoruna etkisi oldukça zayıf.
- Çikolata gramajı arttıkça lezzet skoru artıyor.
- Sol üstteki 2 grafikte tereyağ miktarının artması ile lezzet artışı doğru orantılı gözükürken, sol alttaki grafik, bize 130gr Tereyağ ve 50gr Çikolata olması durumunda skorun düşeceğini gösteriyor. İlk 3 yorumdan farklı olarak sol alttaki grafikte Tereyağ miktarı ile Çikolata miktarı arasındaki etkileşimin skoru ne yönde etkilediğini de görüyoruz.
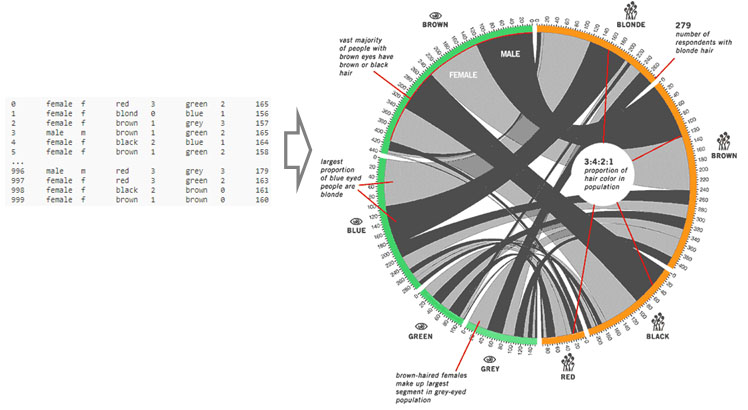
Verilerin görselleştirilerek yorumlanabilir hale gelmesini sağlayan birçok uygulamadan bir taneside Circos Yazılımıdır. Son derece zekice tasarlanmış olan Circos görsellerinde tablo halinde pek de fazla anlam ifade etmeyen yüzlerce veri dairesel bir düzende yorumlanabiliyor. Bu görseller ile faktörlerin birbiri ile ilişki yönü ve gücü, dağılımı, populasyondaki ağırlığı gibi birçok konuda değerlendirme yapabiliyoruz. Görsel 6’da Erkek-Kadın, Göz rengi, saç rengi ve bunlar arasındaki ilişkiyi görebiliyoruz.
Dairesel görsel bize;
- Kahverengi göze sahip insanların çok büyük bir bölümü kahverengi ya da siyah saça sahiptir.
- Kahverengi saçlı kadınlar yeşil gözlerdeki en büyük segmenti oluştururlar,
gibi yorumları sunuyor.
İstatistik bilimi bize; maksimum fayda için kaynakları nasıl kullanmamız gerektiği, gelecekte bizi nelerin beklediği (ben buna zaman yolculuğu diyorum), farkında olmadığımız zayıf ve güçlü yanlarımız, toplumsal eğilimler gibi ihtiyaç duyduğumuz konularda belli ölçülerde güvenilirlikle bilgi sağlar. Güvenilirlik seviyesi veri toplama metodu ve toplanan veri sayısıyla ilişkilidir.
Yeterli seviyede veri elde ettikten sonra teknolojinin bize sunduğu analiz araçlarından ihtiyacımız olanı doğru seçmemiz gerekir. Analiz edilmemiş ve sonuçları değerlendirilmemiş her veri israftır.
Bu yazıyı böyle bir negatif sözle (israf) bitirmeye gönlüm razı olmadı. O yüzden son olarak Pitigrilli’den güzel bir sözle tamamlamak istiyorum.
“Kavramak için görmek, görmek için de dikkatle bakmak gerek.”
Kaynaklar
- http://circos.ca/presentations/articles/vis_tables1/#example1
- https://biruni.tuik.gov.tr/medas/?kn=106&locale=tr
- http://support.sas.com/kb/24/927.html